

引入
1999 年,一个叫约翰·卡马克(John Carmack)在开发《雷神之锤III竞技场》时使用了这么一个算法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16float Q_rsqrt( float number )
{
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // evil floating point bit level hacking
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
return y;
}
这是一个求逆平方根的算法,即:
\begin{equation}
y = \frac{1}{ \sqrt{ x } }
\end{equation}
相信大家在看见i = 0x5f3759df - ( i >> 1 )后,第一反应就和后面的注释一样,what the fuck?这怎么来的?经过一段时间的学习后,我将其推导过程整理如下。
牛顿迭代法
牛顿迭代法是一种近似算法,是专门为求解方程的近似根而生的,看下面的那张图,假如我们要求\( f(x) = 0 \) ,也就是\( A \) 点,但是\( f(x) \)没有求根公式,那咋办?
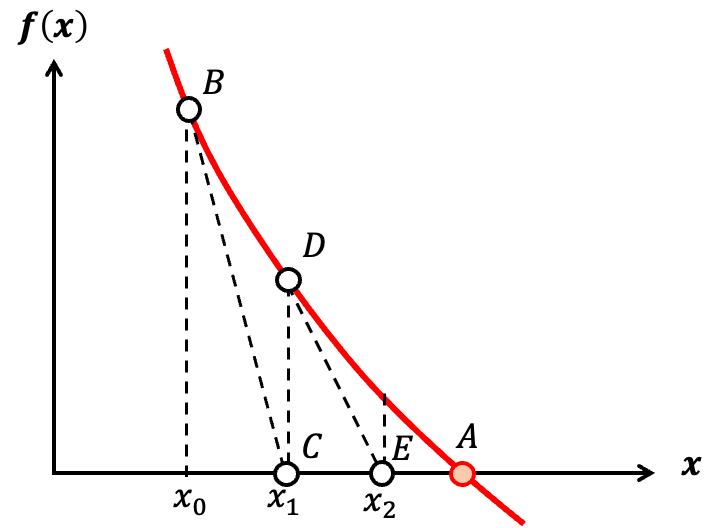
牛顿迭代法就提供了一种方法,他先选择一个初始点\( x_0 \),然后求初始点的切线,求出切线和\( x \)轴的交点\( x_1 \),我们可以看见,\( x_1 \)比\( x_0 \)更“靠近”\( A \)点。如果重复这一步骤,那么在次数足够多的时候,最终的点\( x_n \)和\( A \)点几乎重合。这就是牛顿迭代法的原理。牛顿迭代法的公式为:
\begin{equation}
x_{n+1} = x_n - \frac{f(x_n)}{f’(x_n)}
\end{equation}
回到我们的逆平方根的例子中,假设我们要求\( 1/\sqrt{a} \),即\( f(y) = 1/y^2 - a = 0 \)时,此时牛顿迭代法的公式为:
\begin{equation}
y_{n+1} = \frac{1}{2}y_n(3-ay_n^2)
\end{equation}
对应代码中的y = y * ( threehalfs - ( x2 * y * y ) )。
从牛顿迭代法的原理中我们知道,要想得到精确的结果,要么增加迭代次数,而这样会容易消耗计算机的资源;要么就是取一个非常近似的\( x_0 \),这要只要经过很少次的迭代,甚至只要一次迭代,就能得到一个精确的值。那怎么得到非常近似的\( x_0 \)呢?这就是这个逆平方根算法的精妙之处了。
浮点数在计算机中的表示
IEEE二进制浮点数算术标准(IEEE 754)中规定,在32位单精度浮点数float中,最高的1位是符号位\( S \),接着的8位是指数\( E \),剩下的23位为有效数字\( M \)。即:
\begin{align}
\frac{0}{S}
\frac{01111111}{E}
\frac{10000000000000000000000}{M}
\end{align}
其中有两点需要注意:
指数\( E \)的存储方式为补码,其真实值为\( E - 127 \)。
有效数字\( M \)实际上代表了二进制科学计数法中\( a\cdot2^b \)中的\( a \),比如\( 1.5 \)的二进制科学计数法为\( 1.1 \times 2^0 \),此时\( a = 1.1 \)。故\( a \)的开头总是1,为了节省存储空间,首位的1就不保存。实际上,\( M / 2^{23} = a - 1 \),\( a = 1 + M / 2^{23} \)。
故上面表示的十进制小数为:\( (-1)^S\cdot(1 + M / 2^{23})\cdot2^{E - 127} = 15 \)
而在64位双精度浮点数double中,最高的1位是符号位\( S \),接着的11位是指数\( E \),剩下的52位为有效数字\( M \)。即:
\begin{align}
\frac{
0
}{\text{S}}
\frac{
01111111111
}{\text{E}}
\frac{
10000000000000000000
}{\text{M}}\\
\frac{00000000000000000000000000000000}{\text{M}}
\end{align}
此时十进制小数为:\( (-1)^S\cdot(1 + M / 2^{52})\cdot2^{E - 1023} = 15 \)。
浮点数的对数
上一节的浮点数标准可以看出,一个浮点数被拆成了指数和底数两部分,而指数和底数是可以通过对数联系起来的,我们可以研究一下。
假设\( S \)为0,则一个32位单精度浮点数为\( f = (1 + M / 2^{23})\cdot2^{E - 127} \),\( \log_2{[(1 + M / 2^{23})\cdot2^{E - 127}]} = E - 127 + \log_2{(1 + M / 2^{23})} \),由于\( M / 2^{23} \in [0, 1] \),观察\( \log_2{x} \)在\( [0, 1] \)上的的图像发现,它和\( x \)非常相近:
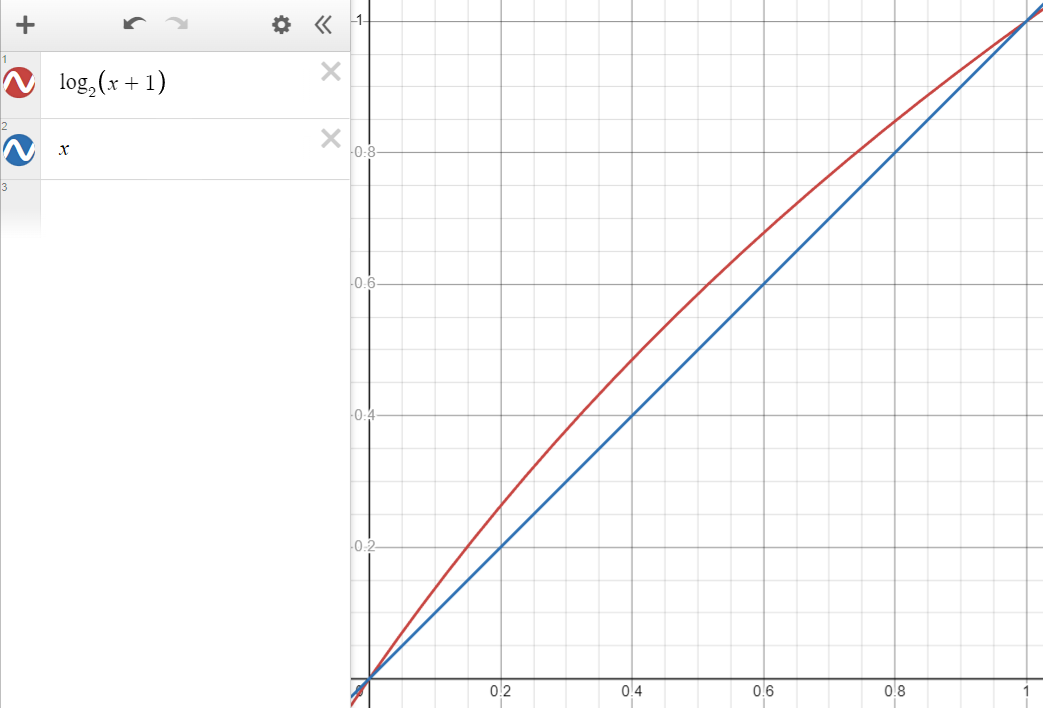
故\( \log_2{(1 + M / 2^{23})}\approx M / 2^{23} \),故:
\begin{equation}
\log_2 f\approx E - 127 + M / 2^{23} = \frac{1}{2^{23}} (2^{23}E + M) - 127
\end{equation}
其中\( 2^{23}E + M \)正好是\( f \)存储在计算机中的形式。
但直接用\( x \)替代\( \log_2{x} \)还是有点粗糙,不妨引入一个\( \sigma \),使得\( \int_0^1|x + \sigma - \log_2{(1+x)|\text{d}x} \)最小。\( y(x) = x + \sigma - \log_2{(1+x)} \)的极值在\( x_0 = 1/\ln2 \)处取得,让\( y(x_0)=\sigma \),则使得\( \int_0^1|x + \sigma - \log_2{(1+x)|\text{d}x} \)在一个比较小的范围内(此时并不是最小!),则求得\( \sigma \approx 0.0430356660279671 \)
逆平方根
按照上面的方法,我们来计算逆平方根的近似值。假设\( g= 1/ \sqrt f \),则\( \log_2 g = -\frac{1}{2}\log_2 f \),令\( F = 2^{23}E_f + M_f \),\( G = 2^{23}E_g + M_g \):
\begin{align}
\frac{1}{2^{23}} G - 127 + \sigma =& -\frac{1}{2}\left(\frac{1}{2^{23}} F - 127 + \sigma\right)\\
G =& \frac{1}{2} F + (127 - \sigma) \times 2^{22} \times 3\\
\approx & \frac{1}{2} F + \text{0x5f37bcb6}
\end{align}
答案已经呼之欲出了,有人可能会说,\( \text{0x5f37bcb6} \)和\( \text{0x5f3759df} \)看着不太一样啊,诚然,我这里取的\( \sigma \)是一个近似值,和卡马克取的\( \sigma \)不一样。
之后的小故事
这之后还有一个有趣的故事。一个来自普渡大学的数学家Chris Lomont看了以后觉得有趣,于是根据理论推导一个最佳猜测值\( \text{0x5f37642f} \),当他信心满满的拿自己计算出的值和卡马克的神秘数字做对比,看看谁的数字能够更快更精确的求得平方根。结果是卡马克赢了… 最后Lomont急了,他用暴力破解的方法,终于找到一个比卡马克数字要好上那么一丁点的数字\( \text{0x5f375a86} \),虽然这两个数字所产生的结果非常近似,谁也不知道卡马克是如何得到那个数字的,卡马克真牛。最后,Lomont把他的成果写成了论文:FAST INVERSE SQUARE ROOT,有兴趣的可以下载下来看看。
还有么
算法中的魔数只能用于32位浮点数,但是我们更多使用的是64位浮点数啊。别急,按照上面的步骤,很容易推导出64位浮点数的魔数。实际上,Lomont已经帮我们推导出来了,为\( \text{0x5fe6ec85e7de30da} \),在FAST INVERSE SQUARE ROOT也能找到。
评论区
欢迎你留下宝贵的意见~